Detecting Anomalies in Industrial Machines Using Sound
Detecting Anomalies in Industrial Machines Using Sound
Integrating CWT and Amazon Bedrock Nova Multimodal Models on the MIMII Dataset
Introduction
Sound-based predictive maintenance has become one of the most promising areas of Industrial AI. Acoustic signals contain rich information about the mechanical state of machines, often complementary to—or even a replacement for—vibration and dedicated physical sensors. However, industrial sound analysis presents significant challenges: signal non-stationarity, environmental noise, machine-to-machine variability, and the scarcity of fault examples.
In this context, combining advanced signal processing techniques, such as the Continuous Wavelet Transform (CWT), with next-generation multimodal foundation models, such as Amazon Bedrock Nova, opens new opportunities for robust and scalable anomaly detection.
The MIMII Dataset (Malfunctioning Industrial Machine Investigation and Inspection) is now one of the reference benchmarks for this domain, providing realistic data of industrial machines operating under both normal and anomalous conditions.
The MIMII Dataset: A Realistic Benchmark
The MIMII Dataset was introduced by Hitachi in the context of the DCASE 2019 workshop with the goal of addressing the lack of public datasets focused on real industrial machine sounds under fault conditions.
Key characteristics of the dataset include:
- Machine types: valves, pumps, fans, and slide rails
- Operating conditions: normal and anomalous sounds
- Anomaly types: contamination, leakage, rotational unbalance, mechanical damage
- Realistic recordings: real factory background noise
- Audio specifications: multi-channel microphone array, 16 kHz sampling rate, 16-bit resolution
The dataset is explicitly designed to evaluate unsupervised and semi-supervised anomaly detection approaches, reflecting real industrial scenarios where faults are rare.
Why the Continuous Wavelet Transform (CWT)
Industrial machine acoustic signals are highly non-stationary: frequency components evolve over time depending on load, speed, and mechanical defects. In such cases, classical FFT-based approaches or even STFT often prove insufficient.
The Continuous Wavelet Transform provides an adaptive time–frequency representation, offering:
- High temporal resolution at high frequencies
- High frequency resolution at low frequencies
- The ability to highlight transients and localized patterns
Formally, the CWT projects a signal onto a family of scaled and translated wavelets, producing a scalogram, which can be interpreted as a 2D time–scale image.
Within the context of the MIMII Dataset, CWT is particularly effective for:
- Highlighting impulsive phenomena related to mechanical damage
- Separating normal operating patterns from subtle anomalies
- Reducing sensitivity to industrial background noise
From Scalograms to the Multimodal Domain
Once the CWT is computed, each audio clip can be transformed into:
- CWT scalograms (time–frequency images)
- Derived statistical features (band energy, entropy, etc.)
This transformation enables a multimodal approach:
- Sound is represented as an image
- Images become natural inputs for Vision-Language / Vision-Like Models (VLMs)
This is where Amazon Bedrock Nova models come into play.
Amazon Bedrock Nova and Multimodal Analysis
Amazon Bedrock Nova is a family of foundation models that includes multimodal embedding models capable of processing text, images, video, and audio within a unified semantic space.
In particular, Amazon Nova Multimodal Embeddings enable:
- Generating embeddings directly from audio or images
- Comparing heterogeneous content types in the same vector space
- Supporting semantic search and anomaly detection workflows
Nova natively supports audio as an input modality and can be seamlessly integrated with custom pipelines based on image representations such as CWT scalograms.
Reference Architecture: CWT + Nova
The proposed architecture for anomaly detection is outlined below:
-
Audio acquisition
Audio clips from the MIMII Dataset (or from field microphones) https://zenodo.org/records/3384388 - CWT and scalogram generation
- Wavelet selection (e.g., Morlet or Morse)
- Conversion to normalized images
- Multimodal embedding with Nova
- Input: image compared with normal image
- Output: high-dimensional embedding vectors
Convert wave to CWT:
import pywt
import numpy as np
import scipy.io.wavfile as wav
def load_and_convert_wav_path(file_path:str, dest_path:str = "temp"):
# 1. Load the audio file
sampling_rate, data = wav.read(file_path)
# Use only one channel if stereo
if len(data.shape) > 1:
data = data[:, 0]
# 2. Perform CWT
# Define scales (frequencies) to analyze
scales = np.arange(1, 128)
# Compute the wavelet transform
coefficients, frequencies = pywt.cwt(data, scales, 'morl')
# 3. Create the scalogram (image)
# Take the absolute value of coefficients
power = (abs(coefficients)) ** 2
# 4. Plot and save
plt.imshow(power, extent=[0, len(data)/sampling_rate, 1, 128],
cmap='jet', aspect='auto', interpolation='bilinear')
image_file_path = os.path.join(dest_path, file_path.replace("/","_").replace("\\","_").replace(".wav",".png"))
plt.title(file_path)
plt.savefig(image_file_path)
plt.show()
return image_file_path
Now you can use the following prompting with Nova Lite
full_user_task = f"""TASK: Anomaly detection by comparison ({str(l)} normal references + 1 target).
Return ONLY JSON:
anomalies
]
}}
DOMAIN CONTEXT:
- Object/scene type: wavelet transform of sound
INSTRUCTIONS:
Is target sound anomalous?
"""
Now let’s compose message for each image references (normal) and the target image (normal or abnormal)
content_json=[]
for i,image_ref in enumerate( image_refs):
content_json.append({ "text": f"Reference {i} (NORMAL):" })
content_json.append(
{
"image": {
"format": media_type,
"source": { "bytes": image_ref }
}
}
)
content_json.append({ "text": "Target T (Target):" })
content_json.append(
{
"image": {
"format": media_type,
"source": { "bytes": image_target }
}
}
)
content_json.append({"text": full_user_task })
messages = [
{
"role": "user",
"content":content_json
}
]
Finally call bedrock AWS Nova lite:
import boto3
MODEL_ID = "eu.amazon.nova-2-lite-v1:0"
bedrock_config = Config(
region_name=os.getenv("AWS_REGION", REGION),
read_timeout=3600,
retries={"max_attempts": 3, "mode": "standard"},
)
client = boto3.client("bedrock-runtime", config=bedrock_config)
response = client.converse(
modelId=MODEL_ID,
system=[{"text": SYSTEM_PROMPT}],
messages=messages,
inferenceConfig={
"maxTokens": max_tokens,
"temperature": 0.0, # please use 0 for json output
"topP": 0.9,
}
)
Below an example of CWT of an abnormal sound:
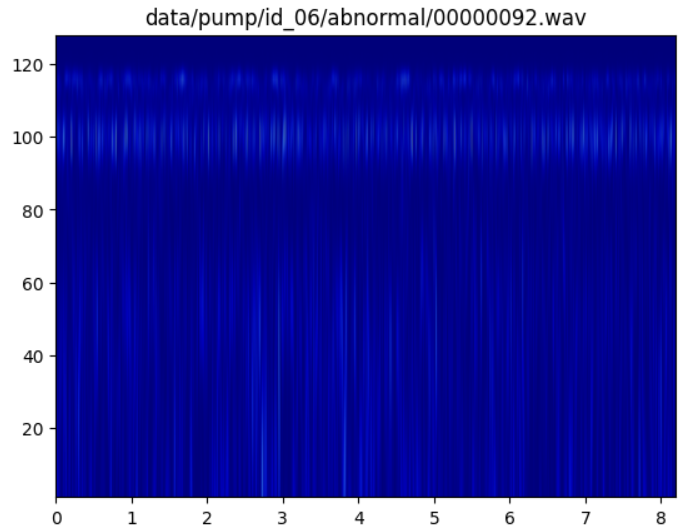
Below the output:
{'anomalies': 'yes', 'findings': [{'description': 'The target spectrogram shows a noticeable reduction in the intensity and frequency of vertical lines compared to the normal references. This suggests a potential anomaly in the sound characteristics, possibly indicating a mechanical issue or abnormal operation in the pump.'}]}
Using pump dataset I got 94% accuracy.
Advantages Over Traditional Approaches
The integration of CWT and Nova offers several advantages over purely end-to-end deep learning pipelines:
- Improved interpretability: scalograms are readable by domain experts
- Domain robustness: multimodal embeddings reduce overfitting to a single machine
- Industrial scalability: Bedrock handles inference, security, and governance
- Reduced labeling effort: naturally suited for unsupervised learning
These aspects are particularly relevant in real industrial environments, as also emphasized by the original goals of the MIMII Dataset.
Conclusions and Outlook
The combined use of Continuous Wavelet Transform and Amazon Bedrock Nova multimodal models represents a powerful and modern approach to industrial sound analysis. The MIMII Dataset provides a solid and realistic foundation for experimenting with these techniques and evaluating their effectiveness in predictive maintenance scenarios.
References:
- Barbosh, M., Dunphy, K. & Sadhu, A. Acoustic emission-based damage localization using wavelet-assisted deep learning. J Infrastruct Preserv Resil 3, 6 (2022). https://doi.org/10.1186/s43065-022-00051-8
- Giacomo Veneri, Pamela Federighi, Francesca Rosini, Antonio Federico, Alessandra Rufa, Spike removal through multiscale wavelet and entropy analysis of ocular motor noise: A case study in patients with cerebellar disease, Journal of Neuroscience Methods, Volume 196, Issue 2, 2011, Pages 318-326, ISSN 0165-0270, https://doi.org/10.1016/j.jneumeth.2011.01.006.
- Barbosh, M., Dunphy, K., & Sadhu, A. (2022). Acoustic emission-based damage localization using wavelet-assisted deep learning. Journal of Infrastructure Preservation and Resilience, 3(1), Article 6. https://doi.org/10.1186/s43065-022-00051-8
- Won, J., Oh, H., & Sakong, J. (2024). Research on the acoustic emission source localization methodology in composite materials based on artificial intelligence. arXiv. https://arxiv.org/abs/2407.05405
- Li, X., Zhang, Y., & Huang, S. (2025). Artificial neural network for classifying fracture mechanisms of pure aluminum based on wavelet transform parameters of acoustic emission signals. Journal of Mechanical Science and Technology. (Springer publication; DOI available in journal record)
- Huang, X., Elshafiey, O., Mukherjee, S., Karim, F., Zhu, Y., Udpa, L., Han, M., & Deng, Y. (2024). Deep learning-assisted structural health monitoring: Acoustic emission analysis and domain adaptation with intelligent fiber optic signal processing. Engineering Research Express, 6(2), 025222. https://doi.org/10.1088/2631-8695/ad48d6
- Wang, X., et al. (2025). Intelligent warning method for fatigue crack propagation stages using acoustic emission and machine learning. Engineering Fracture Mechanics. (Advance online publication)
- Gholizadeh, S., et al. (2024). Continuous wavelet transform and deep learning for accurate acoustic emission zone localization in laminated composites. IEEE Transactions on Instrumentation and Measurement.(IEEE Xplore)
- Alpujiang, J., Ding, S., & Yang, B. (2026). Damage evolution in different reinforcement configurations during four-point bending: Acoustic emission analysis using k-means clustering. Journal of Nondestructive Evaluation. https://doi.org/10.1007/s10921-026-0xxx-x
- Jia, J., & Li, Y. (2023). Deep learning for structural health monitoring: Data, algorithms, applications, challenges, and trends. Sensors, 23(21), 8824. https://doi.org/10.3390/s23218824
- Holford, K. M. (2009). Acoustic emission in structural health monitoring. Key Engineering Materials, 413–414, 15–28. https://doi.org/10.4028/www.scientific.net/KEM.413-414.15
- Ramaguru, G. P., & Pasupuleti, V. D. K. (2025). Voice-enabled structural health monitoring via large language models: A cantilever beam case study. In Proceedings of the International Workshop on Structural Health Monitoring (IWSHM).