My Publications
2025
Enhancing Enterprise-Wide Information Retrieval through RAG Systems Techniques, Evaluation, and Scalable Deployment
ADIPEC 2025
Organizations in the Oil and Gas Industry deal with a vast repository of knowledge dispersed across various structured and unstructured data sources. The process of retrieving information for a particular task can be time-consuming and necessitates the involvement of multiple subject matter experts. Large Language Models (LLMs) supported by Retrieval Augmented Generation (RAG) systems can help expedite information retrieval and processing. However, Enterprise-scale LLM implementation faces challenges, that include confidentiality, scalability, handling hallucinations, handling domain data, feedback, and model improvement. In this technical paper, we describe an optimized RAG system using LLMs for accelerated information retrieval from vast, highly confidential sources. We present the software architecture, the data flow that facilitates the application’s ability to gather feedback for model fine-tuning and the techniques used to optimize our solution for accuracy, scalability, throughput. In the proposed architecture, the LLM-as-a-service component generated an average throughput of 989 tokens per second for summarization tasks involving up to 2500 tokens per request when run on A100 GPUs (40 GB). In the Oil & Gas Industry, the application allows Field Service Engineers to directly retrieve technical details about machinery, details from maintenance manuals etc and helps design teams to speed up information retrieval. This has resulted in an estimated improved productivity in the range of 20% and a positive impact on Customer Relationship, Time to Serve and Cost of Quality.
!(architecture)[/images/soma2025.png]
@proceedings{10.2118/222032-MS,
author = {Palaniappan, Somasundaram and Mali, Rohit and Cuomo, Luca and Vitale, Mauro and Youssef, Ali and Madathil, Athira Puthanveetil and Murugesan, Malathi and Bettini, Alessandro and De Magistris, Giovanni and Veneri, Giacomo},
title = {Enhancing Enterprise-Wide Information Retrieval through RAG Systems Techniques, Evaluation, and Scalable Deployment},
volume = {ADIPEC},
series = {Abu Dhabi International Petroleum Exhibition and Conference},
pages = {D011S020R002},
year = {2024},
month = {11},
abstract = {Organizations in the Oil and Gas Industry deal with a vast repository of knowledge dispersed across various structured and unstructured data sources. The process of retrieving information for a particular task can be time-consuming and necessitates the involvement of multiple subject matter experts. Large Language Models (LLMs) supported by Retrieval Augmented Generation (RAG) systems can help expedite information retrieval and processing. However, Enterprise-scale LLM implementation faces challenges, that include confidentiality, scalability, handling hallucinations, handling domain data, feedback, and model improvement.In this technical paper, we describe an optimized RAG system using LLMs for accelerated information retrieval from vast, highly confidential sources. We present the software architecture, the data flow that facilitates the application's ability to gather feedback for model fine-tuning and the techniques used to optimize our solution for accuracy, scalability, throughput. In the proposed architecture, the LLM-as-a-service component generated an average throughput of 989 tokens per second for summarization tasks involving up to 2500 tokens per request when run on A100 GPUs (40 GB). In the Oil \& Gas Industry, the application allows Field Service Engineers to directly retrieve technical details about machinery, details from maintenance manuals etc and helps design teams to speed up information retrieval. This has resulted in an estimated improved productivity in the range of 20\% and a positive impact on Customer Relationship, Time to Serve and Cost of Quality.},
doi = {10.2118/222032-MS},
url = {https://doi.org/10.2118/222032-MS},
eprint = {https://onepetro.org/SPEADIP/proceedings-pdf/24ADIP/24ADIP/D011S020R002/3840835/spe-222032-ms.pdf},
}2024
Leveraging the Regularizing Effect of Mixing Industrial and Open Source Data to Prevent Overfitting of LLM Fine Tuning
International Joint Conference on Artificial Intelligence 2024 Workshop on AI Governance: Alignment, Morality, and Law
Language models have demonstrated important advancements across various natural language processing (NLP) tasks. However, the availability of high-quality and domain-specific data remains a challenge for training these models, particularly in industry-specific applications. In this paper, we propose a methodology to fine-tune a large language model (LLM) using a mixture of private company data and open-source data. Our empirical investigation reveals that combining private and open-source data during the fine-tuning process leads to superior performance, mitigating the risk of overfitting that can occur when training solely on narrow, domain-specific datasets. We observed that incorporating open-source data alongside the private data helps to reduce the distribution shift between the training and test data, effectively acting as a regularizer and enhancing the model’s ability to generalize. Furthermore, we compare the divergence between the private and open-source datasets with the test loss of the fine-tuned model. Our results suggest a correlation between reduced data divergence and improved model performance, indicating that carefully selecting and curating the dataset mixture can be a crucial step in preventing overfitting and ensuring the model’s effective adaptation to industry-specific use cases. This study provides a practical solution for industry-specific adaptation of LLMs, demonstrating how the strategic blending of private and open-source data can unlock the full potential of these models while addressing critical concerns around data privacy and model reliability in real-world applications.
@inproceedings{
jebali2024leveraging,
title={Leveraging the Regularizing Effect of Mixing Industrial and Open Source Data to Prevent Overfitting of {LLM} Fine Tuning},
author={Mohamed Salah Jebali and Anna Valanzano and Malathi Murugesan and Giacomo Veneri and Giovanni De Magistris},
booktitle={International Joint Conference on Artificial Intelligence 2024 Workshop on AI Governance: Alignment, Morality, and Law},
year={2024},
url={https://openreview.net/forum?id=zaYwh5pPPO}
}Controllable Image Synthesis of Industrial Data Using Stable Diffusion
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Training supervised deep neural networks that perform defect detection and segmentation requires large-scale fully-annotated datasets, which can be hard or even impossible to obtain in industrial environments. Generative AI offers opportunities to enlarge small industrial datasets artificially, thus enabling the usage of state-of-the-art supervised approaches in the industry. Unfortunately, also good generative models need a lot of data to train, while industrial datasets are often tiny. Here, we propose a new approach for reusing general-purpose pre-trained generative models on industrial data, ultimately allowing the generation of self-labelled defective images. First, we let the model learn the new concept, entailing the novel data distribution. Then, we force it to learn to condition the generative process, producing industrial images that satisfy well-defined topological characteristics and show defects with a given geometry and location. To highlight the advantage of our approach, we use the synthetic dataset to optimise a crack segmentor for a real industrial use case. When the available data is small, we observe considerable performance increase under several metrics, showing the method’s potential in production environments.
@InProceedings{Valvano_2024_WACV,
author = {Valvano, Gabriele and Agostino, Antonino and De Magistris, Giovanni and Graziano, Antonino and Veneri, Giacomo},
title = {Controllable Image Synthesis of Industrial Data Using Stable Diffusion},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {5354-5363}
}2023
Combining Thermodynamics-based Model of the Centrifugal Compressors and Active Machine Learning for Enhanced Industrial Design Optimization
Ghiasi, Shadi and Pazzi, Guido and Del Grosso, Concettina and De Magistris, Giovanni and Veneri, Giacomo
The design process of centrifugal compressors requires applying an optimization process which is computationally expensive due to complex analytical equations underlying the compressor’s dynamical equations. Although the regression surrogate models could drastically reduce the computational cost of such a process, the major challenge is the scarcity of data for training the surrogate model. Aiming to strategically exploit the labeled samples, we propose the Active-CompDesign framework in which we combine a thermodynamics-based compressor model (i.e., our internal software for compressor design) and Gaussian Process-based surrogate model within a deployable Active Learning (AL) setting. We first conduct experiments in an offline setting and further, extend it to an online AL framework where a real-time interaction with the thermodynamics-based compressor’s model allows the deployment in production. ActiveCompDesign shows a significant performance improvement in surrogate modeling by leveraging on uncertainty-based query function of samples within the AL framework with respect to the random selection of data points. Moreover, our framework in production has reduced the total computational time of compressor’s design optimization to around 46% faster than relying on the internal thermodynamics-based simulator, achieving the same performance.

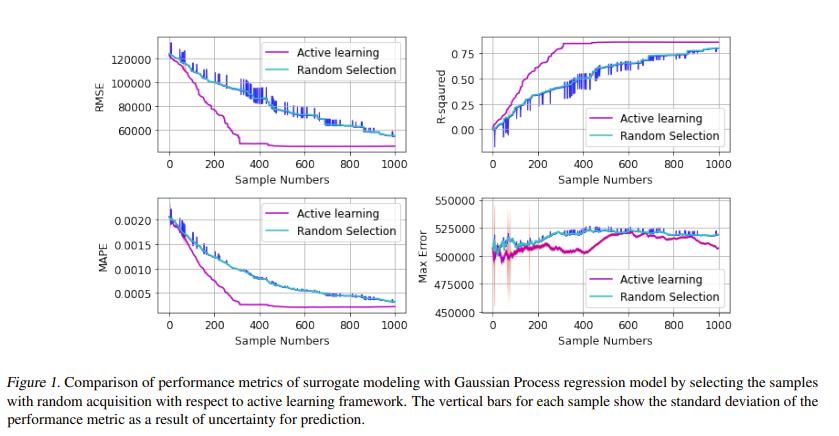
@inproceedings{ghiasi2023combining,
title={Combining Thermodynamics-based Model of the Centrifugal Compressors and Active Machine Learning for Enhanced Industrial Design Optimization},
author={Ghiasi, Shadi and Pazzi, Guido and Del Grosso, Concettina and De Magistris, Giovanni and Veneri, Giacomo},
booktitle={1st Workshop on the Synergy of Scientific and Machine Learning Modeling@ ICML2023},
year={2023}
}Sensor Virtualization for Anomaly Detection of Turbo-Machinery Sensors—An Industrial Application
Shetty, Sachin, Valentina Gori, Gianni Bagni, and Giacomo Veneri. 2023
We apply a Granger causality and auto-correlation analysis to train a recurrent neural network (RNN) that acts as a virtual sensor model. These models can be used to check the status of several hundreds of sensors during turbo-machinery units’ operation. Checking the health of each sensor is a time-consuming activity. Training a supervised algorithm is not feasible because we do not know all the failure modes that the sensors can undergo. We use a semi-supervised approach and train an RNN (LSTM) on non-anomalous data to build a virtual sensor using other sensors as regressors. We use the Granger causality test to identify the set of input sensors for a given target sensor. Moreover, we look at the auto-correlation function (ACF) to understand the temporal dependency in data. We then compare the predicted signal vs. the real one to raise (in case) an anomaly in real time. Results report 96% precision and 100% recall.
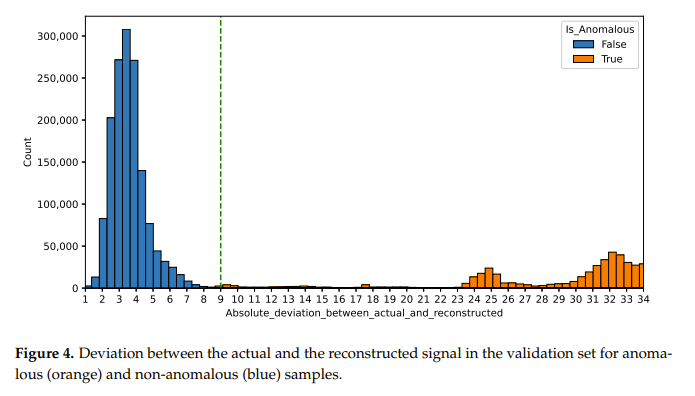
@Article{engproc2023039096,
AUTHOR = {Shetty, Sachin and Gori, Valentina and Bagni, Gianni and Veneri, Giacomo},
TITLE = {Sensor Virtualization for Anomaly Detection of Turbo-Machinery Sensors—An Industrial Application},
JOURNAL = {Engineering Proceedings},
VOLUME = {39},
YEAR = {2023},
NUMBER = {1},
ARTICLE-NUMBER = {96},
URL = {https://www.mdpi.com/2673-4591/39/1/96},
ISSN = {2673-4591},
ABSTRACT = {We apply a Granger causality and auto-correlation analysis to train a recurrent neural network (RNN) that acts as a virtual sensor model. These models can be used to check the status of several hundreds of sensors during turbo-machinery units’ operation. Checking the health of each sensor is a time-consuming activity. Training a supervised algorithm is not feasible because we do not know all the failure modes that the sensors can undergo. We use a semi-supervised approach and train an RNN (LSTM) on non-anomalous data to build a virtual sensor using other sensors as regressors. We use the Granger causality test to identify the set of input sensors for a given target sensor. Moreover, we look at the auto-correlation function (ACF) to understand the temporal dependency in data. We then compare the predicted signal vs. the real one to raise (in case) an anomaly in real time. Results report 96% precision and 100% recall.},
DOI = {10.3390/engproc2023039096}
}Also see anomalies definition from Anomaly Detection Definition
@book{veneri2018,
title={Hands-on industrial Internet of Things: create a powerful industrial IoT infrastructure using industry 4.0},
author={Veneri, Giacomo and Capasso, Antonio},
year={2018},
publisher={Packt Publishing Ltd}
}2022
Document Layout Analysis with Variational Autoencoders: An Industrial Application
- Ali Youssef, Gabriele Valvano, Giacomo Veneri *
- ISMIS 2022. Lecture Notes in Computer Science *
We present a novel method for Document Layout Analysis that detects documents that are not compliant with a given template. The major challenge we solve is dealing with a highly unbalanced dataset with only a few, hard-to-distinguish, non-compliant documents. Our model learns to detect inadequate documents based on localised non-compliant characteristics, including stamps, handwritten text, and misplaced signatures. Nevertheless, the model must not report documents containing other artefacts such as amendments or notes, which we deem acceptable. We address these challenges via generative modelling, using anomaly detection techniques to validate document layout. In particular, we first let the model learn the compliant document distribution. Then, we detect and report out-of-distribution samples for their automated rejection. In the paper, we investigate and compare two major approaches to anomaly …
@inproceedings{youssef2022document,
title={Document Layout Analysis with Variational Autoencoders: An Industrial Application},
author={Youssef, Ali and Valvano, Gabriele and Veneri, Giacomo},
booktitle={International Symposium on Methodologies for Intelligent Systems},
pages={477--486},
year={2022}
}Deep Surrogate of Modular Multi Pump using Active Learning
-
Malathi Murugesan, Kanika Goyal, Laure Barriere, Maura Pasquotti, Giacomo Veneri, Giovanni De Magistris *
-
Adaptive Experimental Design and Active Learning in the Real World - ICML 2022 *
Due to the high cost and reliability of sensors, the designers of a pump reduce the needed number of sensors for the estimation of the feasible operating point as much as possible. The major challenge to obtain a good estimation is the low amount of data available. Using this amount of data, the performance of the estimation method is not enough to satisfy the client requests. To solve this problem of scarcity of data, getting high quality data is important to obtain a good estimation. Based on these considerations, we develop an active learning framework for estimating the operating point of a Modular Multi Pump used in energy field. In particular we focus on the estimation of the surge distance. We apply Active learning to estimate the surge distance with minimal dataset. Results report that active learning is a valuable technique also for real application.
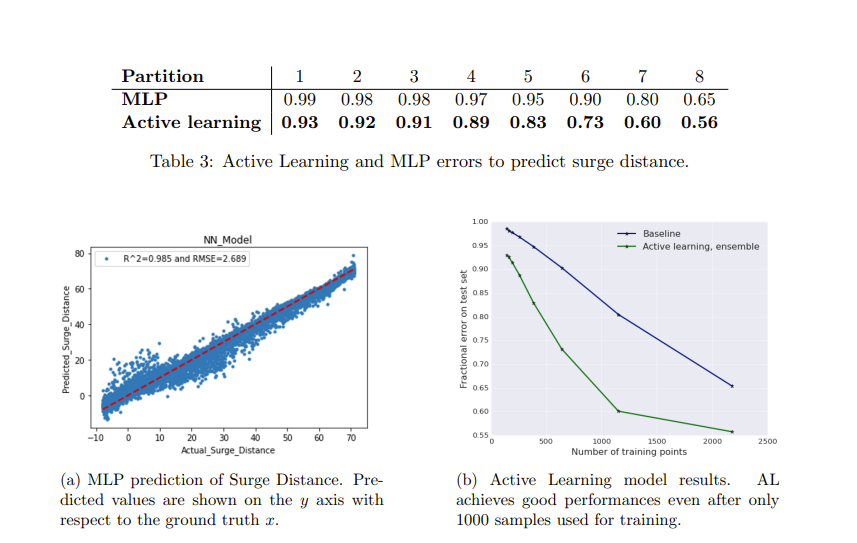
@article{murugesandeep,
title={Deep Surrogate of Modular Multi Pump using Active Learning},
author={Murugesan, Malathi and Goyal, Kanika and Barriere, Laure and Pasquotti, Maura and Veneri, Giacomo and De Magistris, Giovanni}
booktitle={Adaptive Experimental Design and Active Learning in the Real World - ICML 2022},
year={2022}
}2021
DANNTe: a case study of a turbo-machinery sensor virtualization under domain shift
- Strazzera, Luca and Gori, Valentina and Veneri, Giacomo *
We propose an adversarial learning method to tackle a Domain Adaptation (DA) time series regression task (DANNTe). The regression aims at building a virtual copy of a sensor installed on a gas turbine, to be used in place of the physical sensor which can be missing in certain situations. Our DA approach is to search for a domain-invariant representation of the features. The learner has access to both a labelled source dataset and an unlabeled target dataset (unsupervised DA) and is trained on both, exploiting the minmax game between a task regressor and a domain classifier Neural Networks. Both models share the same feature representation, learnt by a feature extractor. This work is based on the results published by Ganin et al. arXiv:1505.07818; indeed, we present an extension suitable to time series applications. We report a significant improvement in regression performance, compared to the baseline model trained on the source domain only.

@inproceedings{strazzera2021dannte,
title={DANNTe: a case study of a turbo-machinery sensor virtualization under domain shift},
author={Strazzera, Luca and Gori, Valentina and Veneri, Giacomo},
booktitle={NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications},
year={2021}
}2020
Learning to Identify Drilling Defects in Turbine Blades with Single Stage Detectors
- Panizza Andrea, Szymon Tomasz Stefanek, Stefano Melacci, Veneri Giacomo, Marco Gori *
- Proceedings of NeurIPS 2020 Workshop on Machine Learning for Engineering Modeling, Simulation and Design *
Nondestructive testing (NDT) is widely applied to defect identification of turbine components during manufacturing and operation. Operational efficiency is key for gas turbine OEM (Original Equipment Manufacturers). Automating the inspection process as much as possible, while minimizing the uncertainties involved, is thus crucial. We propose a model based on RetinaNet to identify drilling defects in X-ray images of turbine blades. The application is challenging due to the large image resolutions in which defects are very small and hardly captured by the commonly used anchor sizes, and also due to the small size of the available dataset. As a matter of fact, all these issues are pretty common in the application of Deep Learning-based object detection models to industrial defect data. We overcome such issues using open source models, splitting the input images into tiles and scaling them up, applying heavy data augmentation, and optimizing the anchor size and aspect ratios with a differential evolution solver. We validate the model with 3-fold cross-validation, showing a very high accuracy in identifying images with defects. We also define a set of best practices which can help other practitioners overcome similar challenges.
@article{panizzalearning,
title={Learning to Identify Drilling Defects in Turbine Blades with Single Stage Detectors},
author={Panizza, Andrea and Stefanek, Szymon Tomasz and Melacci, Stefano and Veneri, Giacomo and Gori, Marco}
booktitle={Proceedings of NeurIPS 2020 Workshop on Machine Learning for Engineering Modeling, Simulation and Design},
year={2020}
}